![]()
■構文解析(parser)
![]()
2005年10月4日 20:35 更新
1. はじめに
コンパイラを構成する処理要素のうち、「1. 字句解析」によって、プログラム中のトークン(命令語やリテラル)を切り出した後の段階では、そのトークンの属性と文法に記述された構文規則に基づいて、導出木を構成する必要がある。この処理を「構文解析(parser)」と呼ぶ。コンパイラ内部で導出木の構成作業を行うような機能モジュールを「構文解析器」と呼ぶ。
字句解析器の入力トークンは文字(と[EOF])である。構文解析器の入力トークンは字句トークンである。
構文規則の決定のため、定義されたトークンを用いて記述した、単調BNF(Backus Naur Form)あるいは拡張BNF形式を用いて文法を作成する。
文法の表現の仕方には、大きく分けて以下の2つがある。
・規則の上から下へ向けて生成する方法(下降型:LL法)
・規則の下から上へ向けて生成する方法(上昇型:LR法)
下降型は、数式や論理関数をスタックマシンなどで逐次実行する場合にはLL法で記述しておいて直接実行(変換)できるなど便利だが、反面、左再帰(例:E → E '+' T といった生成規則)を許さないなど条件が厳しい、高級言語系の自動生成に向かないなど欠点もある。LL法を使用している構文解析器としては、javacc などが有名である。
他方、上昇型は、例えばLR法の場合、導出木の生成のために変換表(LR表と呼ばれる決定性オートマトン)を利用するため導出アルゴリズムが若干複雑であるが、左再帰を許しており、拡張BNFがそのまま利用できる、プログラム言語系の自動生成に向いているなど、数々の利点を有している。
今回の演習で使用しているSableCC parser generatorでは、LALR法 を採用している。LA とは "Look-Ahead" の略で、字句トークンを読み込み導出木を生成する際、先読み操作を行う工夫のことである。LALR(1)構文解析では、最初からLR(1)項を考えるのではなく、LR表(決定性オートマトン)の状態の中の各項に、先読み記号(の集合)を「飾り」として付加する。LALR(1)を使用している構文解析器としては、他に yacc などが有名である。
2. 準備
2.1 簡単な文法ファイル
2.2 test1.grammarの説明
2.3 SableCCによる構文解析器の生成とテスト
2.1 簡単な文法ファイル
先の test0.grammar 文法ファイルに対して、乗算('*')と括弧('(' , ')')の非終端記号を追加した、test1.grammar 文法ファイルについて、最初に示しておく。
(説明上、左端に行番号を付した。実際の文法ファイル中に行番号は付されていない)
演算の評価の優先順位は、(括弧) > '*' > '+' でなければならない。ボトムアップ型構文解析のため、この逆の親子関係で構文規則を記述する。
<文法ファイル:test1.grammar>
1 Package test1;
2
3 Tokens
4 number = [ '0' .. '9' ]+;
5 plus = '+';
6 mult = '*';
7 l_par = '(';
8 r_par = ')';
9 blank = ( ' ' | 13 | 10 )+;
10
11 Ignored Tokens
12 blank;
13
14 Productions
15 expr =
16 {term} term |
17 {plus} expr plus term;
18
19 term =
20 {factor} factor |
21 {mult} term mult factor;
22
23 factor =
24 {number} number |
25 {expr} l_par expr r_par;
|
この文法ファイルは、「整数リテラル同士の加算・乗算(括弧あり)」を記述したものである。
具体的には、以下の例のような文字列を受理するようなものである。([EOF]は入力シーケンスの終端を示す)
例:
3 * 4 + 5[EOF]
6 * ( 7 + 8 )[EOF]
2.2 test1.grammarの説明
※SableCCの文法ファイル形式はここから参照されたい。
http://sablecc.org/grammars/sablecc-2x.sablecc.web.html
簡単な文法ファイルの例(test1.grammar)について、各ディレクティブについて説明する。
3-9行目(Tokensディレクティブ):
字句規則を指定している。test0.grammarに対して、以下の3種類のトークンを追加して定義している。各々の意味付けは以下の通り。
mult :'*'が1つ並んだ列("乗算"を表す2項演算子)
l_par :'('が1つ並んだ列(左括弧)
r_par :')'が1つ並んだ列(右括弧)
14-25行目(Productionsディレクティブ):
構文規則を指定している。
ここでは、expr, term に加えて factor というラベルが付された3つの規則を定義している。規則exprの内部でterm, 規則termの内部で factor が使われているため、3つの規則には親子関係があり、expr > term > factor である。トークン plus, mult, number は、各々 expr, term, factor 内部で利用されている。各々の規則の意味は以下の通り。
規則expr:
{ラベルterm} :term が出現する
あるいは
{ラベルplus} :expr '+' term (加算の演算式)が出現する(終わり)。
規則term:
{ラベルfactor} :factor が出現する
あるいは
{ラベルmult} :term '*' factor (乗算の演算式)が出現する(終わり)。規則factor:
{ラベルnumber} :number(整数リテラル)が出現する
あるいは
{ラベルexpr} :'(' expr ')' (左右括弧の内部に演算式)が出現する(終わり)。
2.3 SableCCによる構文解析器の生成とテスト
付録A. SableCCのインストール、5. 実行試験 を参考にして、今回は、test1.grammar試験用プロジェクトファイルを新たにビルドして、構文解析器を生成してみよう。
test1プロジェクトファイルはここからダウンロード(test1-src.tar.gz)
実際に、加算・乗算の式("3 * 4 + 5[EOF]"など)を解析器(test1.jar)に入力した場合の実行結果を以下に示す。
実行結果は、test1.tool.PrintTreeクラスによって、導出木全体を深さ優先探索した結果で表示されている。
<実行結果1:"3 * 4 + 5[EOF]">
$ echo "3 * 4 + 5" | java -jar test1.jar
Start
APlusExpr
ATermExpr
AMultTerm
AFactorTerm
ANumberFactor
TNumber: 3
TMult: *
ANumberFactor
TNumber: 4
TPlus: +
AFactorTerm
ANumberFactor
TNumber: 5
EOF:
|
<実行結果2:"6 * ( 7 + 8 )[EOF]">
$ echo "6 * ( 7 + 8 )" | java -jar test1.jar
Start
ATermExpr
AMultTerm
AFactorTerm
ANumberFactor
TNumber: 6
TMult: *
AExprFactor
TLPar: (
APlusExpr
ATermExpr
AFactorTerm
ANumberFactor
TNumber: 7
TPlus: +
AFactorTerm
ANumberFactor
TNumber: 8
TRPar: )
EOF:
|
3. LR構文解析
LR (Left-to-right, Right-parse) 構文解析は、上昇型構文解析 (bottom-up parsing) のひとつである。
上昇型構文解析の基本的な考え方は、
(1)入力を読みながら導出木を少しずつ作る
(2)読んだ入力を使って、導出木のできる限り大きな部分を作る
(3)それ以上大きくできなかったら次の文字を読む
という手順にある。
LR構文解析は、導出木の生成のために、LR表と呼ばれる決定性オートマトンを作成しこれを駆動することで実行される。LR表の各エントリーが一意に定まるような文法をLR(1)という。
3.1 LR文法/受理する入力列/導出木の例
3.2 構文解析器の構成
3.3 LR解析表
3.4 LR表を用いた解析例
3.1 LR文法/受理する入力列/導出木の例
A. 文法の例(test1.grammarと同等)
終端記号 '+' '*' '(' ')' Num
非終端記号 Expr Term Factor
開始記号 Expr生成規則:
(1) Expr → Expr '+' Term
(2) Expr → Term
(3) Term → Term '*' Factor
(4) Term → Factor
(5) Factor → '(' Expr ')'
(6) Factor → Num
B. 上記の文法が受理する入力列の例( $ は入力終端を表す[EOF]と同じ)
Num '*' Num '+' Num $
Num '*' '(' Num '+' Num ')' $ など
C. 導出木の例(構築後)
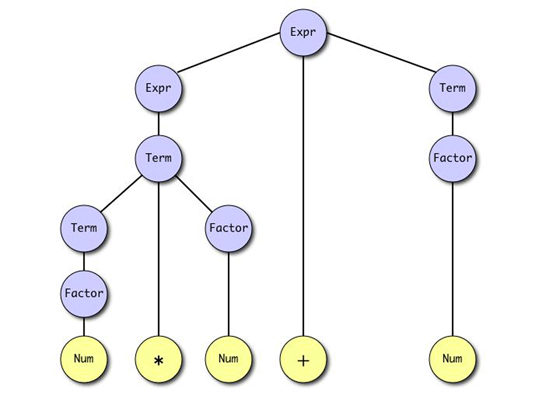
図2.1: Num '*' Num '+' Num $ の導出木
3.2 構文解析器の構成
構文解析器は、図2.2に示すプッシュダウンオートマトンに基づくモデル(スタックマシン)が用いられる。
構文解析プログラムは、予め与えられた文法から生成された解析表(決定性オートマトン)と使用する。状態値はスタックにプッシュしていく。入力トークン列(テープ)を先頭から順次読み、スタックの状態値と、入力テープの内容に従って、状態遷移を行っていく。その際、導出木を順次成長させる。
入力テープが終端($ EOF)へ至った後、スタック先頭の状態値が「受理」状態に到達すれば、解析は正常に終了している。
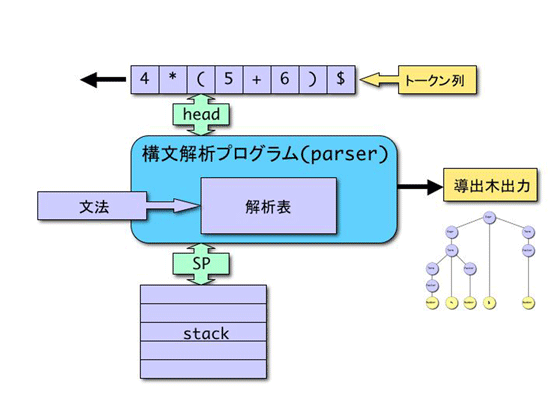
図2.2: スタックマシンによる構文解析器の構成
3.3 LR解析表
SLR (simple LR) 構文解析の解析表(以下LR解析表)を例を用いて説明する。これは、先の文法(3.1.A)(生成規則)に対するSLR パーサである。(なお、この文法は 参考文献[1] の 例 6.1 でとりあげられている文法である。 なお、構文解析についての一般理論(拡大文法)ならびに、生成規則から解析表を作成する詳しい手順については、このAho/Ullman本を参照のこと。)
導出木の生成は、以下のLR解析表に基づいて行われる。LR表は、予め与えられた文法から生成されたものである。LR表では、解析器のスタックのトップにおかれた状態と、入力される先頭字句トークンによって次の動作を決める。
状態0から開始し、字句トークンの終端($)に至った際に「受理」状態1まで到達しておれば、正常に解析が終わっている。
表2.1 は、先の文法(3.1.A)のLR表である。STATEは状態値、actionはその状態値で受付可能なトークンの種類を示している。
ある状態値における、入力トークンの種類に応じた動作の切り替えと、次の状態値への遷移は、actionの S5, R2 といった記号で指示されている。これは、各々、「シフト」と「還元」と呼ばれる動作である。シフト (shift) は次の文字を読む操作、 還元 (reduce) は生成規則を逆に適用して、読んだ文字列を非終端記号に置き換える操作である。
表2.1: 文法(3.1.A)のLR解析表
-----------------------------------------------------------
STATE action next state
Num + * ( ) $ Expr Term Factor
-----------------------------------------------------------
0 S5 S4 1 2 3
1 S6 受理
2 R2 S7 R2 R2
3 R4 R4 R4 R4
4 S5 S4 8 2 3
5 R6 R6 R6 R6
6 S5 S4 9 3
7 S5 S4 10
8 S6 S11
9 R1 S7 R1 R1
10 R3 R3 R3 R3
11 R5 R5 R5 R5
-----------------------------------------------------------
|
具体的には、表2.1の場合、
状態0 : token Num --> action = S5 (shift Num, and state 5):
スタックに Num をプッシュする。次に、遷移先の状態値 5 をスタックにプッシュする。
状態5 : token '*' --> action = R6 (reduce using rule#6):
スタック先頭の Num をポップする。6番目の生成規則 Factor -> Num を逆向きに使って、Num を Factor で置き換える。スタック先頭には、Numをプッシュする前の状態値(状態0)が入っているので、解析表の状態値0の行における、next state : Factor のカラムの値(状態3)から、次の状態が決まる。最後に、Factor と 遷移先の状態値 3 をスタックにプッシュする。
LR表の actionのエントリが空白の箇所は「解析エラー」つまり入力された字句トークンの列が、規定された文法に沿っていない場合である。例えば、
Num '*' '(' Num '+' Num ')' $ → 受理
Num '*' '(' Num '+' Num $ → 解析エラー(対応する右括弧が出現せず終端となっている)
現在の状態値と、入力されたトークンの種別によって、何が原因で解析エラーに至ったのかを判断して、レポートを出力することができる。また、場面によっては、ある程度のエラーの修復(リカバリ)も行うことができる。
3.4 LR表を用いた解析例
入力 Num * Num + Num $ に対する解析例を、表2.2に示す。
ここで、非終端記号は、E:Expr, T:Term, F:Factor のように1文字に簡略して表記した。
表2.2: 入力 Num * Num + Num $ に対する解析例
----------------------------------------------------------------- STEP stack(--->head) <--- token input output(node) ----------------------------------------------------------------- (1) 0 Num * Num + Num $ (2) 0 Num 5 * Num + Num $ (3) 0 F 3 * Num + Num $ Num <- F (4) 0 T 2 * Num + Num $ F <- T (5) 0 T 2 * 7 Num + Num $ (6) 0 T 2 * 7 Num 5 + Num $ (7) 0 T 2 * 7 F 10 + Num $ Num <- F (8) 0 T 2 + Num $ T * F <- T (9) 0 E 1 + Num $ T <- E (10) 0 E 1 + 6 Num $ (11) 0 E 1 + 6 Num 5 $ (12) 0 E 1 + 6 F 3 $ Num <- F (13) 0 E 1 + 6 T 9 $ F <- T (14) 0 E 1 $ E + T <- E ----------------------------------------------------------------- |
動作は、3.3節に説明した通り、シフト/還元とスタックへの状態値とNumのプッシュによって、順次行われる。スタックには、初期状態として先頭に 0 がセットされている。
STEP(1) :
状態0 : token Num --> action = S5 (shift Num, and state 5):
スタックに Num をプッシュする。次に、遷移先の状態値 5 をスタックにプッシュする。
stack [0:Num:5]↓
STEP(2):
状態5 : token '*' --> action = R6 (reduce using rule#6):
スタック先頭の 状態値5, Num をポップする。6番目の生成規則 Factor -> Num を逆向きに使って、Num を Factor で置き換える(Num <- F)。スタック先頭には、Numをプッシュする前の状態値(状態0)が入っているので、解析表の状態値0の行における、next state : Factor のカラムの値(状態3)から、次の状態が決まる。最後に、F(Factor) と 遷移先の状態値 3 をスタックにプッシュする。
stack [0:F:3] , output [Num <- F]↓
STEP(3):
状態3 : token '*' --> action = R4 (reduce using rule#4):
スタック先頭の 状態値3, Num をポップする。4番目の生成規則 Term -> Factor を逆向きに使って、Factor を Term で置き換える(T <- F)。スタック先頭には、Numをプッシュする前の状態値(状態0)が入っているので、解析表の状態値0の行における、next state : Term のカラムの値(状態2)から、次の状態が決まる。最後に、T(Term) と 遷移先の状態値 2 をスタックにプッシュする。
stack [0:T:2] , output [T <- F]↓
<途中省略>
STEP(13):
..............
stack [0:E:1] , output [E + T <- E]↓
STEP(14):
状態1:token $ --> action = 受理 :
スタック先頭の 状態値1, E をポップする。終端記号 $ 入力時の action は「受理」であるので、ここで解析は正常に終了した。
4. 構文解析器の実際
test1.grammar文法ファイルに基づいて、SableCCによって字句解析器(parser.Parser class)が生成される。
生成されたJavaソースファイルの、解析表(決定性オートマトン)に基づいて構文解析処理を行っている部分(parseメソッド)の抜粋を以下に示す。
(説明上、左端に行番号を付した。実際の文法ファイル中に行番号は付されていない)
src/test1/parser/Parser.java(ファイル全体:461行)
1 /* This file was generated by SableCC (http://www.sablecc.org/). */
2
3 package test1.parser;
4
5 import test1.lexer.*;
6 import test1.node.*;
7 import test1.analysis.*;
8 import java.util.*;
9
10 import java.io.DataInputStream;
11 import java.io.BufferedInputStream;
12 import java.io.IOException;
13
14 public class Parser
15 {
....中略....
111 public Start parse() throws ParserException, LexerException,
IOException
112 {
113 push(0, null, true);
114 List ign = null;
115 while(true)
116 {
....次の字句トークンを読み込み....
// 行列カウント処理....
133 last_pos = lexer.peek().getPos();
134 last_line = lexer.peek().getLine();
135 last_token = lexer.peek();
136
137 int index = index(lexer.peek());
138 action[0] = actionTable[state()][0][1];
139 action[1] = actionTable[state()][0][2];
140
141 int low = 1;
142 int high = actionTable[state()].length - 1;
....現在の状態値とトークン種別に対するactionを決定....
// ここから、シフト/還元処理を実行
164 switch(action[0])
165 {
166 case SHIFT:
167 {
168 ArrayList list = new ArrayList();
169 list.add(lexer.next());
170 push(action[1], list, false);
171 last_shift = action[1];
172 }
173 break;
174 case REDUCE:
175 switch(action[1])
176 {
177 case 0: /* reduce ATermExpr */
178 {
179 ArrayList list = new0();
180 push(goTo(0), list, false);
181 }
182 break;
183 case 1: /* reduce APlusExpr */
184 {
185 ArrayList list = new1();
186 push(goTo(0), list, false);
187 }
188 break;
189 case 2: /* reduce AFactorTerm */
190 {
191 ArrayList list = new2();
192 push(goTo(1), list, false);
193 }
194 break;
195 case 3: /* reduce AMultTerm */
196 {
197 ArrayList list = new3();
198 push(goTo(1), list, false);
199 }
200 break;
201 case 4: /* reduce ANumberFactor */
202 {
203 ArrayList list = new4();
204 push(goTo(2), list, false);
205 }
206 break;
207 case 5: /* reduce AExprFactor */
208 {
209 ArrayList list = new5();
210 push(goTo(2), list, false);
211 }
212 break;
213 }
214 break;
....[EOF]まで到達していたら、正常に解析終了....
215 case ACCEPT:
216 {
217 EOF node2 = (EOF) lexer.next();
218 PExpr node1 = (PExpr) ((ArrayList)pop()).get(0);
219 Start node = new Start(node1, node2);
220 return node;
221 }
....非対応のトークンであれば、解析エラー&行列表示....
222 case ERROR:
223 throw new ParserException(last_token,
224 "[" + last_line + "," + last_pos + "] " +
225 errorMessages[errors[action[1]]]);
226 }
227 }
228 }
....中略....
232 ArrayList new0() /* reduce ATermExpr */
250 ArrayList new1() /* reduce APlusExpr */
274 ArrayList new2() /* reduce AFactorTerm */
292 ArrayList new3() /* reduce AMultTerm */
316 ArrayList new4() /* reduce ANumberFactor */
334 ArrayList new5() /* reduce AExprFactor */
....解析表のテーブルの実体(actionテーブル、gotoTableテーブル)....
358 private static int[][][] actionTable;
359 /* {
360 {{-1, ERROR, 0}, {0, SHIFT, 1}, {3, SHIFT, 2}, },
361 {{-1, REDUCE, 4}, },
362 {{-1, ERROR, 2}, {0, SHIFT, 1}, {3, SHIFT, 2}, },
363 {{-1, ERROR, 3}, {1, SHIFT, 7}, {5, ACCEPT, -1}, },
364 {{-1, REDUCE, 0}, {2, SHIFT, 8}, },
365 {{-1, REDUCE, 2}, },
366 {{-1, ERROR, 6}, {1, SHIFT, 7}, {4, SHIFT, 9}, },
367 {{-1, ERROR, 7}, {0, SHIFT, 1}, {3, SHIFT, 2}, },
368 {{-1, ERROR, 8}, {0, SHIFT, 1}, {3, SHIFT, 2}, },
369 {{-1, REDUCE, 5}, },
370 {{-1, REDUCE, 1}, {2, SHIFT, 8}, },
371 {{-1, REDUCE, 3}, },
372 };*/
373 private static int[][][] gotoTable;
374 /* {
375 {{-1, 3}, {2, 6}, },
376 {{-1, 4}, {7, 10}, },
377 {{-1, 5}, {8, 11}, },
378 };*/
....中略....
461 }
|
![]()

wasaki@cs.shinshu-u.ac.jp
Copyright(c) 2006 Katsumi Wasaki. All rights reserved.